
Review: DeepMind's Breakthrough in Math Reasoning

Google DeepMind’s AlphaProof system won a silver medal in the International Math Olympiad, outperforming 90% of the mathematically gifted high school competitors. This achievement marks a significant advancement in AI's problem-solving capabilities, and it’s worth understanding what tells us about the extent of AI’s problem solving capabilities.
This post outlines my understanding of why large language models (LLMs) have struggled with math problem-solving, how Google’s approach with AlphaProof improves this, and the new questions this success raises.
Why LLMs have failed at math reasoning:
LLMs have faced difficulties in solving math proofs due to the lack of an automated scoring function, making efficient training challenging.
Consider the following training example: let’s say we have a proof problem (string A) with a known valid proof (string B). During training, an LLM generates a proposed proof (string B’). How would you validate whether the proof is valid and the weights that generated it should be reinforced in training, or vice versa?
Well, if B’ matches B exactly word-for-for, it’s easy to score it as correct. But if B’ doesn’t match B exactly, validating its correctness becomes hard. Minor differences can invalidate a proof, but significant differences vs. a known valid proof might still be valid. Your options are to either have a mathematician manually evaluate each proposed proof (extremely time and cost-intensive), or probabilistically validate based on whether the proofs are semantically similar (high error rate).
Note - this challenge doesn’t apply to chatbot LLMs, because probabilistic semantic similarity is enough. Responses don’t have to be as logically consistent or accurate as in math proofs (and in fact, chatbot LLMs famously struggle with logic & accuracy).
Google’s Approach:
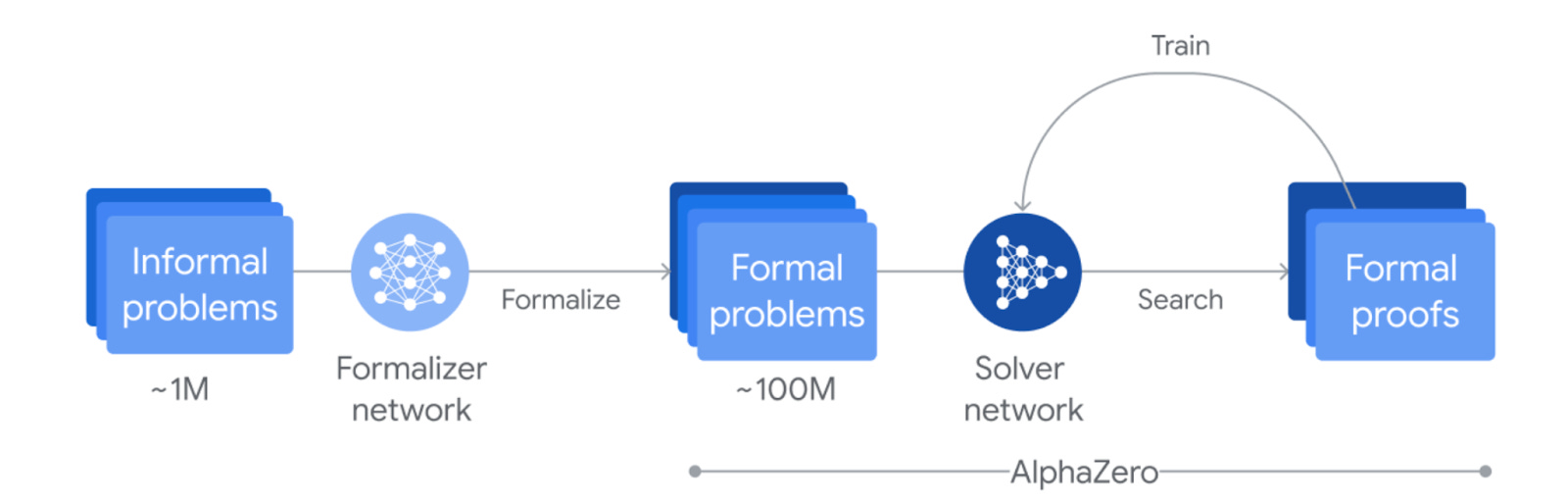
Using Formal Math Language (Lean) for input & output: Lean automatically validates the correctness of proposed proofs, providing an automated scoring function & solving the core challenge above.
Reinforcement Learning (RL): They employed the AlphaZero RL algorithm, which doesn’t require valid problem-solution datasets, addressing the scarcity of formal language problem-solution data.
Fine-Tuned Gemini LLM: To bootstrap a problem-only training set in formal language, serving as the input for the RL algorithm (which needs to be in formal language for automatic validation to work).
The outcome was P90 performance in the IMO. And interestingly, quirks of trial-and-error based reinforcement learning approach show up in “unorthodox” and “quirky” proofs produced by AlphaZero.
Learnings & new questions:
The key takeaway is that combining formal languages with reinforcement learning can yield better results than LLMs alone for tasks requiring precise and accurate outputs.
This success prompts two important questions:
Will formal language plus RL remain the superior approach for complex AI problem-solving long-term, or simply the first one to yield a promising solution?
Can this approach be applied to other domains that use formal languages, such as programming?